Category: research
18 Jul 2023
.
research
.
New position at Durham University
Comments

As of 1st September 2023, I will be taking up a position as Assistant Professor in Visual Computing at Durham University working in the VIViD group. This marks a major transition for me, as I move from being a contract-based Assistant Professor (or Researcher RTDa in the Italian system) to a permanent member of staff (i.e. Lecturer).
As part of this transition, I’m looking for PhD students to join me in Durham. With an interest in Spatial Reasoning especially in the context of Cultural Heritage and the Arts. To give an idea of the work I’m interested in, I’ve included a brief description of my research interests below. If you are interested in working with me, please get in touch!
Research Focus: Bridging cultural analytics and knowledge graphs via neuro-symbolic reasoning
The ability of AI to provide assistive tools for the inspections and interrogation of humanities data at scale (i.e. distant reading) while preserving fine-grained analysis (i.e. close reading) relies on more than the information in the observation but linking it with the wealth of human experience and knowledge to deduce useful correlations. However, embedding such knowledge within Artificial Intelligence (AI) tools is challenging as it relies on building a complex representation of the meaning behind items or events. Such complex meaning is commonplace in the arts and cultural heritage, where the meaning behind an item (or its depicted content) is highly interlinked with culture and history. Overcoming the disconnect between visual content and knowledge would allow new and impactful insights, helping to shape the future directions of society. In addition, increased access to knowledge through question and answering and its visual equivalent.
05 Feb 2023
.
research
.
Two New EU Projects kicking off 2023: DCitizens & BoSS
Comments

This year we see the kick-off of two new projects Bauhaus of the Seas (BOSS) and DCitizens. Two projects focused on citizens and communities with very exciting prospects. Check them out!
DCitizens project…
DCitizens aims to foster Digital Civics research and innovation in Lisbon. Digital Civics is a cross-disciplinary field that posits the use of technology to empower citizens and non-state actors to co-create, take an active role in shaping agendas, make decisions about service provision, and make such provisions sustainable and resilient. Particularly how digital technologies can scaffold a move from transactional to relational service models and the potential of such models to reconfigure power relations between citizens, communities, and institutions.
Find out more at: https://dcitizens.eu/
Bauhaus of the Seas project…
The vision of the Bauhaus of the Seas is to demonstrate and archive solutions for climate neutrality with a particular focus on coastal cities as an interface to healthy seas, ocean and water bodies envisioning a new triangle of sustainability, inclusion, and design focused on the most important global natural space – our water bodies. The BoS will offer opportunities to engage with communities for an environmentally sustainable, socially fair, and aesthetically appealing transition. Currently, seven cities, located in four different regions and aquatic ecosystems in Portugal (estuary), Italy (lagoon and gulf), Sweden/Germany (strait/river), and the Netherlands/Belgium (delta) have committed to the Bauhaus of the Seas network supporting mission-oriented pilots of the New European Bauhaus and showcase innovative solutions.
Find out more at: https://bauhaus-seas.eu/
03 Dec 2020
.
research
.
Three great videos about the pilot locations of MEMEX
Comments
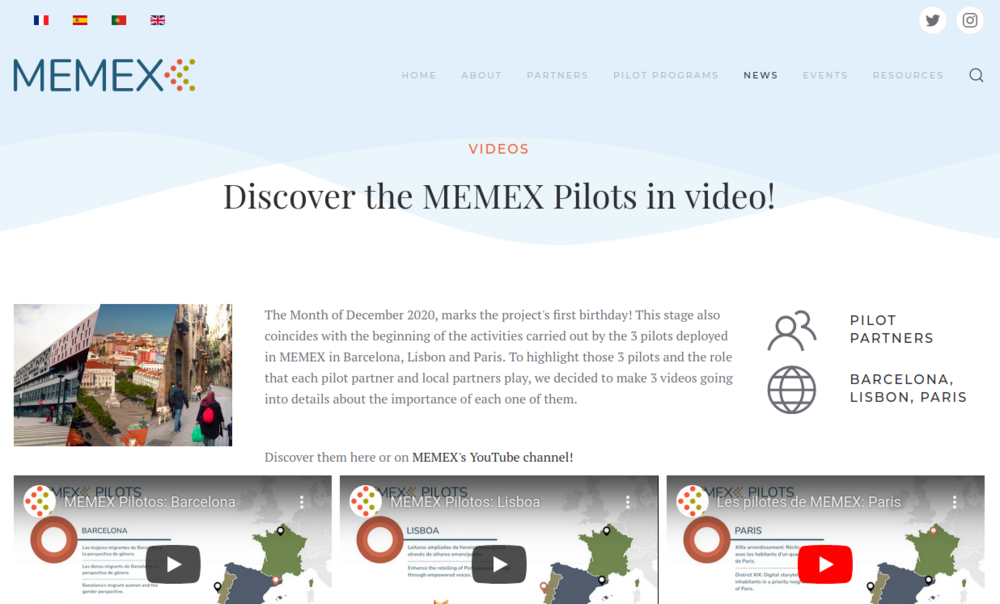
We recently published three videos on the pilot locations, Paris, Barcelona and Spain, of the MEMEX Project. This challenging collaboration effort came together during the second wave of COVID so a massive effort was needed by the Michael Culture Association, NOHO Limited, Fundacio Interarts per a la Cooperacio Cultural Internacional (InterArts), Mapas das Ideias and Dédale.
About the project…
The MEMEX project promotes social cohesion through collaborative, heritage-related tools that provide inclusive access to tangible and intangible cultural heritage and, at the same time, facilitate encounters, discussions and interactions between communities at risk of social exclusion. These tools will empower communities of people with the possibility of welding together their fragmented experiences and memories into compelling and geolocalised storylines using new personalised digital content linked to the pre-existent European Cultural Heritage (CH). The tools of MEMEX will allow the communities to tell their stories and to claim their rights and equal participation in European society. To this end, MEMEX will nurture actions that contribute to, rather than undermine, practices of recognition of differences by giving voice to individuals for promoting cultural diversity.
24 Aug 2020
.
research
.
Two positions on MEMEX Project (Post Doc and Engineer)
Comments

We have two (exciting) positions to join us on the MEMEX EU Project! One engineer to coordinate with the project consortium to develop an innovative app exposing Cultural Heritage and project participant stories. The second is a post-doc to research and develop algorithms for 3D Scene Understanding! These are two very exciting positions to work with us and create impactful tools and research.
About the project…
The MEMEX project promotes social cohesion through collaborative, heritage-related tools that provide inclusive access to tangible and intangible cultural heritage and, at the same time, facilitate encounters, discussions and interactions between communities at risk of social exclusion. These tools will empower communities of people with the possibility of welding together their fragmented experiences and memories into compelling and geolocalised storylines using new personalised digital content linked to the pre-existent European Cultural Heritage (CH). The tools of MEMEX will allow the communities to tell their stories and to claim their rights and equal participation in the European society. To this end, MEMEX will nurture actions that contribute to, rather than undermine, practices of recognition of differences by giving voice to individuals for promoting cultural diversity.
Project Site: https://memexproject.eu/
Post Doc
The research topics on 3D scene understanding are related to the recent PAVIS achievements on Spatial AI related to 3D semantic mapping, object 3D localization, graph neural networks (GNNs) for scene modelling and active visual reasoning by integrating deep learning models with multi-view geometry approaches. Such methods will leverage massive worldwide geolocalised data as provided by project partners to finally deploy a mobile app that understands, localizes and reason about the semantic elements present in a generic scene.
Engineer
The candidate will have the opportunity to work on realistic problems involving leading European research centers and companies with the aim to create a novel AR platform able to understand the semantic scene structure of the environment using an RGB video stream from a smartphone.
Application Details
To apply, follow the instructions indicated at the following links:
Engineer Position: https://iit.taleo.net/careersection/ex/jobdetail.ftl?lang=en&job=2000002M
Post Doc Position: https://iit.taleo.net/careersection/ex/jobdetail.ftl?lang=en&job=2000002K
18 May 2020
.
research
.
New PhD Position Available in Visual Reasoning!
Comments

Exciting news, for me and possibly for you! This post marks my first PhD call where I will be leading the research direction of the successful candidate in collaboration with Alessio Del Bue (IIT) and Sebastiano Vascon (Ca’ Foscari University of Venice). So, we are looking for someone with interest in pursuing a PhD in Visual Reasoning to join the Pattern Analysis and Computer Vision Department of the Italian Institute of Technology (IIT). The University of Genova are the awarding body of this PhD, so please be careful of the details which can be found on the University of Genova website.
Theme F: Visual Reasoning with Knowledge and Graph Neural Networks for scene understanding
Machine ability to detect objects within images has surpassed human ability, however, when posed with relatively simple more complex tasks machines quickly struggle. This theme focuses on developing AI systems that are able to access knowledge stored in Knowledge Graphs to understand the world around the camera view. Few works have successfully integrated knowledge in Computer Vision systems and knowledge graphs provide one avenue. This research will study methods to integrate knowledge for user interaction via retrieval or visual question and answering within real world environments. In particular, shallow and deep graph-based methodologies are promising computational framework to include external knowledge and also maintaining a high degree of interpretability, a necessary feature for modern AI systems.
** There are other themes check them out to work in our department **
Application Details
To apply, follow the instructions indicated at the following links where the notice of public examination in Italian and in English are published:
https://unige.it/en/usg/en/phd-programmes
https://unige.it/en/students/phd-programmes
In short, the documentation to be submitted is a detailed CV, a research proposal under one or more themes chosen among Theme K or the other themes (please, see also a project proposal template at the link indicated below), reference letters, and any other formal document concerning the degrees earned.
Please note that these documents are mandatory in order to consider valid the application.
IMPORTANT: In order to apply, candidates must prepare a research proposal based on the research topics above mentioned.
Please, follow these indications to prepare it:
https://pavisdata.iit.it/data/phd/ResearchProjectTemplate.pdf
ONLINE APPLICATION DEADLINE is June 15th, 2020 at 12:00 p.m. (noon, Italian time/CEST)
STRICT DEADLINE, NO EXTENSION.
Additional Links:
Disclaimer
Please note your in-name supervisor will be Dr. Alessio Del Bue who leads the Pattern Analysis and Computer Vision department, however, your research activities will be led by myself. The Italian application process applies to a call, not a tutor/supervisor, where supervisor are selected based on the most suitable.
10 Jan 2020
.
research
.
And it begins... MEMEX
Comments

Today we had our Kick-off Meeting for the MEMEX EU Project here is the abstract:
MEMEX promotes social cohesion through collaborative, heritage-related storytelling tools that provide access to tangible and intangible Cultural Heritage (CH) for communities at risk of exclusion. The project implements new actions for social science to: understand the NEEDS of such communities and co-design interfaces to suit their needs; DEVELOP the audience through participation strategies; while increasing the INCLUSION of communities. The fruition of this will be achieved through ground breaking ICT tools that provide a new paradigm for interaction with CH for all end user. MEMEX will create new assisted Augmented Reality (AR) experiences in the form of stories that intertwine the memories (expressed as videos, images or text) of the participating communities with the physical places / objects that surround them. To reach these objectives, MEMEX develop techniques to (semi-)automatically link images to their LOCATION and connect to a new opensource Knowledge Graph (KG). The KG will facilitate assisted storytelling by means of clustering that links consistently user data and CH assets in the KG. Finally, stories will be visualised onto smartphones by AR on top of the real world allowing to TELL an engaging narrative. MEMEX will be deployed and demonstrated on three pilots with unique communities. First, Barcelona’s Migrant Women, which raises the gender question around their inclusion in CH, giving them a voice to valorise their memories. Secondly, MEMEX will give access to the inhabitants of Paris’s XIX district, one of the largest immigrant settlements of Paris, to digital heritage repositories of over 1 million items to develop co-authored new history and memories connected to the artistic history of the district. Finally, first, second and third generation Portuguese migrants living in Lisbon will provide insights on how technology tools can enrich the lives of the participants.
More information coming soon at www.memexproject.eu or on EU Cordis https://cordis.europa.eu/project/id/870743
25 Sep 2019
.
research
.
Review in a week*
Comments

For a long time now, I have been reviewing articles at a variety of journals and conferences, which is “usually” tracked within publons. While I try hard to make sure that I get reviews completed before the deadline often, when it comes to Journals, this is accomplished in the final few days before the deadline. This creates a significant stress and anxiety to my academic life, as I’m constantly worrying about the tasks that I have to do, and in some cases staying up late to get the review completed. Therefore, as I review my activities, I consider how I can improve the way I review, and therefore I propose (not originally) review in a week*.
While I (generally) steadily increase in review articles per year, it becomes more critical to review effectively.

So I put this out there, that going forward, my goal is to review journal articles within a week* of accepting them. For anyone even partially observant I am diligent in including an asterisk after this statement. Naturally, this is for a good reason; a 20+ page article isn’t sensible to keep to this goal or if I’m very aware that I can not complete due to other commitments, e.g. travel. However, within a week of office time, the review will be complete.
There is a second part to this that is saying “No”. If I’m accepting articles I’m not excited about then this goal will be significantly hard to achieve. Therefore, hand-in-hand, I will be more proactive in saying no to articles that don’t interest me.
As I consider it essential to evaluate any objective; therefore, at the end of 2019, I will review this progress. Which gives me a wonderful excuse to create graphs of my progress (which all academics enjoy), but I will have to put some thought into what to plot.
So Journals! Let’s see what you have install for September-December of 2019.
18 Apr 2018
.
research
.
Organising VisArt @ ECCV'18!
Comments

This year I’m very excited to be organising the workshop VISART IV with several other great chairs:
- Alessio Del Bue, Istituto Italiano di Tecnologia (IIT);
- Leonardo Impett, EPFL & Biblioteca Hertziana, Max Planck for Art History;
- Peter Hall, University of Bath;
- Joao Paulo Costeira, ISR, Instituto Superior Técnico;
- Peter Bell, Friedrichs-Alexander University Nüremberg.
We hope that this year pushes harder the collaboration between Computer Vision, Digital Humanities and Art History. With aims to generate some fantastic new partnerships to be published at this workshop and future ones.
The further bonding is exemplified by the new track to allow DH and Art History to join the conversation about what they are doing with Computer Vision and how we can help them in the future. I’m very excited to see what gets submitted.
So here is the Call for Papers, enjoy!
VISART IV “Where Computer Vision Meets Art” Pre Announcement
4th Workshop on Computer VISion for ART Analysis In conjunction with the 2018 European Conference on Computer Vision (ECCV), Cultural Center (Kulturzentrum Gasteig), Munich, Germany
IMPORTANT DATES Full & Extended Abstract Paper Submission: July 9th 2018 Notification of Acceptance: August 3rd 2018 Camera-Ready Paper Due: September 21st 2018 Workshop: 9th September 2018
CALL FOR PAPERS
Following the success of the previous editions of the Workshop on Computer VISion for ART Analysis held in 2012, 2014 and 2016, we present the VISART IV workshop, in conjunction with the 2018 European Conference on Computer Vision (ECCV 2018). VISART will continue its role as a forum for the presentation, discussion and publication of computer vision techniques for the analysis of art. In contrast with prior editions, VISART IV will expand its remit, offering two tracks for submission:
- Computer Vision for Art - technical work (standard ECCV submission, 14 page excluding references)
- Uses and Reflection of Computer Vision for Art (Extended abstract, 4 page, excluding references)
The recent explosion in the digitisation of artworks highlights the concrete importance of application in the overlap between computer vision and art; such as the automatic indexing of databases of paintings and drawings, or automatic tools for the analysis of cultural heritage. Such an encounter, however, also opens the door both to a wider computational understanding of the image beyond photo-geometry, and to a deeper critical engagement with how images are mediated, understood or produced by computer vision techniques in the ‘Age of Image-Machines’ (T. J. Clark). Whereas submissions to our first track should primarily consist of technical papers, our second track therefore encourages critical essays or extended abstracts from art historians, artists, cultural historians, media theorists and computer scientists.
The purpose of this workshop is to bring together leading researchers in the fields of computer vision and the digital humanities with art and cultural historians and artists, to promote interdisciplinary collaborations, and to expose the hybrid community to cutting-edge techniques and open problems on both sides of this fascinating area of study.
This one-day workshop in conjunction with ECCV 2018, calls for high-quality, previously unpublished, works related to Computer Vision and Cultural History. Submissions for both tracks should conform to the ECCV 2018 proceedings style. Papers must be submitted online through the CMT submission system at:
https://cmt3.research.microsoft.com/VISART2018/
and will be double-blind peer reviewed by at least three reviewers.
TOPICS include but are not limited to:
- Art History and Computer Vision
- 3D reconstruction from visual art or historical sites
- Artistic style transfer from artworks to images and 3D scans
- 2D and 3D human pose estimation in art
- Image and visual representation in art
- Computer Vision for cultural heritage applications
- Authentication Forensics and dating
- Big-data analysis of art
- Media content analysis and search
- Visual Question & Answering (VQA) or Captioning for Art
- Visual human-machine interaction for Cultural Heritage
- Multimedia databases and digital libraries for artistic and art-historical research
- Interactive 3D media and immersive AR/VR environments for Cultural Heritage
- Digital recognition, analysis or augmentation of historical maps
- Security and legal issues in the digital presentation and distribution of cultural information
- Surveillance and behaviour analysis in Galleries, Libraries, Archives and Museums
INVITED SPEAKERS
- Peter Bell (Professor of Digital Humanities - Art History, Friedrich- Alexander University Nüremberg)
- Bjorn Ommer (Professor of Computer Vision, Heidelberg)
- Eva-Maria Seng (Chair of Tangible and Intangible Heritage, Faculty of Cultural Studies, University of Paderborn)
- More speakers TBC
PROGRAM COMMITTEE
To be confirmed.
ORGANIZERS: Alessio Del Bue, Istituto Italiano di Tecnologia (IIT) Leonardo Impett, EPFL & Biblioteca Hertziana, Max Planck for Art History Stuart James, Istituto Italiano di Tecnologia (IIT) Peter Hall, University of Bath Joao Paulo Costeira, ISR, Instituto Superior Técnico Peter Bell, Friedrichs-Alexander University Nüremberg
25 Apr 2017
.
research
.
Texture Stationarization: Turning Photos into Tileable Textures
Comments

I’m very proud to announce our recent paper at Eurographics 2017 in Lyon today the spotlight was showcased, with narration by Joep Moritz. If you didn’t get the chance to see it, an extended version is now available on YouTube.
06 Apr 2017
.
research
.
Leaving UCL meal with Tim's group
Comments

After being with Tim Weyrich’s group for almost a year and a half yesterday we had our final group lunch and a cheeky beer. It has been great working with everyone at UCL, not just in the immediate group and in that vain more shenanigans to come.
26 Aug 2016
.
research
.
Transferring old book image style to real world photos
Comments

Style transfer has become a popular area of research and with public applications such as Prisma based on Neural Style Transfer [Gatys'15]. Earlier this week I wanted to answer the question does it really work for understanding the larger style and context. In contrast to [Wang'13] where they learnt an artistic stroke style, how does it compare. The British Library Flickr 1m+ dataset [BL'13] provides an interesting application of this, where there is an inherent style for transferring.
So having read the papers around this previously, I was fairly sure it would not transfer very well, but on the chance that local statistics can enforce something coherent it was worth running (and also gave me a chance to play with such networks). So by taking a few examples, these are the best results from transferring from the BL'13 to the Berkeley Segmentation Dataset (BSDS500) [BSDS500'11]

These results were achieved using the Texture Nets method [Ulyanov'16] trained on a singular example and the most visually appealing results displayed after playing with the Texture / Style weights as well as the chosen example. Code available on GitHub



What is quite interesting is if you look at this from a distance they look plausible, but it isn't till you look at one adjacent to another or zoom in you realize that these aren't actually the same style. Logical hatching patterns to describe shadows or depth are ignored, or in the cases where they are present they don't make sense.
As a mini-conclusion, style-transfer, although gaining a lot of hype has still a long way to being accurately reproduced general artistic style. Still the results are interesting and if you aren't looking for exact replication, then it is visually appealing. It must be bared in mind that the British Library dataset is challenging, where the style has been evolving for human understanding over millenniums. A problem to keep working on, possibly guided by transfer learning.
References
[Gatys'15] Leon A Gatys and Alexander S Ecker and Matthias Bethge. "A Neural Algorithm of Artistic Style". Arxiv (http://arxiv.org/abs/1508.06576). 2015.
[Wang'13] T Wang and J Collomosse and D Greig and A Hunter. "Learnable Stroke Models for Example-based Portrait Painting". Proc. British Machine Vision Conference (BMVC). 2013.
[BL'13] British Library Flickr. https://www.flickr.com/photos/britishlibrary/. 2013.
[BSDS500'11] Berkeley Segmentation Dataset. https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/resources.html#bsds500. 2011
[Ulyanov'16] Dmitry Ulyanov and Vadim Lebedev and Andrea Vedaldi and Victor Lempitsky. "Texture Networks: Feed-forward Synthesis of Textures and Stylized Images. Arxiv (http://arxiv.org/abs/1603.03417). 2016.
20 Apr 2016
.
research
.
Working with the British Library Dataset
Comments

Earlier this year Tim Weyrich directed me onto a dataset published by the British Library and since then my research has focused heavily around this. Within Computer Vision it is unusual to get a large dataset not skewed to achieve a specific research goal. Sometimes datasets can be repurposed, but this is requires extensive effort to get the data in its rawest form.
The British Library dataset is a quite literally a "dump" of all the unknown to OCR elements from the book scanning performed by Microsoft. Therefore is not just a collection of line art imagery, but also of elaborate charachters or section embroidery.
I intend to post more on working with this dataset as time goes on, but for now there is a github which contains the directory of images: Directory of Images (Github)
And what is the main repository on Flickr:Flickr Repository
07 Jul 2014
.
research
.
libSVM linear kernel normalisation
Comments
I have used a variety of tools for binary, multiclass and even incremental SVM problems, today I found something quite nice in binary case for libSVM, although potentially a source of confusion.
It is common in machine learning to apply a sigmoid function to normalise the boundaries of a problem, this can by empirically defining the upper and lower bound or through experimentation. Within libSVM they do this through experimentation, that is great to save you some time. The only thing to remember is it means through the use of random and cross validation with small sets of data, you are likely to get different results on each run.
So the function to consider is this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
// Cross-validation decision values for probability estimates
static void svm_binary_svc_probability(
const svm_problem *prob, const svm_parameter *param,
double Cp, double Cn, double& probA, double& probB)
{
int i;
int nr_fold = 5;
int *perm = Malloc(int,prob->l);
double *dec_values = Malloc(double,prob->l);
// random shuffle
for(i=0;i<prob->l;i++) perm[i]=i;
for(i=0;i<prob->l;i++)
{
int j = i+rand()%(prob->l-i);
swap(perm[i],perm[j]);
}
for(i=0;i<nr_fold;i++)
{
int begin = i*prob->l/nr_fold;
int end = (i+1)*prob->l/nr_fold;
int j,k;
struct svm_problem subprob;
subprob.l = prob->l-(end-begin);
subprob.x = Malloc(struct svm_node*,subprob.l);
subprob.y = Malloc(double,subprob.l);
k=0;
for(j=0;j<begin;j++)
{
subprob.x[k] = prob->x[perm[j]];
subprob.y[k] = prob->y[perm[j]];
++k;
}
for(j=end;j<prob->l;j++)
{
subprob.x[k] = prob->x[perm[j]];
subprob.y[k] = prob->y[perm[j]];
++k;
}
int p_count=0,n_count=0;
for(j=0;j<k;j++)
if(subprob.y[j]>0)
p_count++;
else
n_count++;
if(p_count==0 && n_count==0)
for(j=begin;j<end;j++)
dec_values[perm[j]] = 0;
else if(p_count > 0 && n_count == 0)
for(j=begin;j<end;j++)
dec_values[perm[j]] = 1;
else if(p_count == 0 && n_count > 0)
for(j=begin;j<end;j++)
dec_values[perm[j]] = -1;
else
{
svm_parameter subparam = *param;
subparam.probability=0;
subparam.C=1.0;
subparam.nr_weight=2;
subparam.weight_label = Malloc(int,2);
subparam.weight = Malloc(double,2);
subparam.weight_label[0]=+1;
subparam.weight_label[1]=-1;
subparam.weight[0]=Cp;
subparam.weight[1]=Cn;
struct svm_model *submodel = svm_train(&subprob,&subparam);
for(j=begin;j<end;j++)
{
svm_predict_values(submodel,prob->x[perm[j]],&(dec_values[perm[j]]));
// ensure +1 -1 order; reason not using CV subroutine
dec_values[perm[j]] *= submodel->label[0];
}
svm_free_and_destroy_model(&submodel);
svm_destroy_param(&subparam);
}
free(subprob.x);
free(subprob.y);
}
sigmoid_train(prob->l,dec_values,prob->y,probA,probB);
free(dec_values);
free(perm);
}
So if you have few numbers of samples, that is the case in some circumstances then the cross validation is where you hit problems. Of course you can simply re-implement it yourself or you can add a few lines to stop cross validation if the number of samples is too few.<p>
</p><p>Not the most elegant of code, but for the moment it will do. I choose to completely seperate the two steps as opposed to multiple if’s</p><pre class="brush: c++; toolbar: false">static void svm_binary_svc_probability(
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
const svm_problem *prob, const svm_parameter *param,
double Cp, double Cn, double& probA, double& probB)
{
int i;
int nr_fold = 5;
int *perm = Malloc(int,prob->l);
double *dec_values = Malloc(double,prob->l);
// random shuffle
for(i=0;i<prob->l;i++) perm[i]=i;
for(i=0;i<prob->l;i++)
{
int j = i+rand()%(prob->l-i);
swap(perm[i],perm[j]);
}
if (prob->l < (5*nr_fold)){
int begin = 0;
int end = prob->l;
int j,k;
struct svm_problem subprob;
subprob.l = prob->l;
subprob.x = Malloc(struct svm_node*,subprob.l);
subprob.y = Malloc(double,subprob.l);
k=0;
for(j=0;j<prob->l;j++)
{
subprob.x[k] = prob->x[perm[j]];
subprob.y[k] = prob->y[perm[j]];
++k;
}
int p_count=0,n_count=0;
for(j=0;j<k;j++)
if(prob->y[j]>0)
p_count++;
else
n_count++;
if(p_count==0 && n_count==0)
for(j=begin;j<end;j++)
dec_values[perm[j]] = 0;
else if(p_count > 0 && n_count == 0)
for(j=begin;j<end;j++)
dec_values[perm[j]] = 1;
else if(p_count == 0 && n_count > 0)
for(j=begin;j<end;j++)
dec_values[perm[j]] = -1;
else
{
svm_parameter subparam = *param;
subparam.probability=0;
subparam.C=1.0;
subparam.nr_weight=2;
subparam.weight_label = Malloc(int,2);
subparam.weight = Malloc(double,2);
subparam.weight_label[0]=+1;
subparam.weight_label[1]=-1;
subparam.weight[0]=Cp;
subparam.weight[1]=Cn;
struct svm_model *submodel = svm_train(&subprob,&subparam);
for(j=begin;j<end;j++)
{
svm_predict_values(submodel,prob->x[perm[j]],&(dec_values[perm[j]]));
// ensure +1 -1 order; reason not using CV subroutine
dec_values[perm[j]] *= submodel->label[0];
}
svm_free_and_destroy_model(&submodel);
svm_destroy_param(&subparam);
}
free(subprob.x);
free(subprob.y);
}else{
for(i=0;i<nr_fold;i++)
{
int begin = i*prob->l/nr_fold;
int end = (i+1)*prob->l/nr_fold;
if (nr_fold == 1){
begin = 0 ;
end = prob->l;
}
int j,k;
struct svm_problem subprob;
subprob.l = prob->l-(end-begin);
subprob.x = Malloc(struct svm_node*,subprob.l);
subprob.y = Malloc(double,subprob.l);
k=0;
for(j=0;j<begin;j++)
{
subprob.x[k] = prob->x[perm[j]];
subprob.y[k] = prob->y[perm[j]];
++k;
}
for(j=end;j<prob->l;j++)
{
subprob.x[k] = prob->x[perm[j]];
subprob.y[k] = prob->y[perm[j]];
++k;
}
int p_count=0,n_count=0;
for(j=0;j<k;j++)
if(subprob.y[j]>0)
p_count++;
else
n_count++;
if(p_count==0 && n_count==0)
for(j=begin;j<end;j++)
dec_values[perm[j]] = 0;
else if(p_count > 0 && n_count == 0)
for(j=begin;j<end;j++)
dec_values[perm[j]] = 1;
else if(p_count == 0 && n_count > 0)
for(j=begin;j<end;j++)
dec_values[perm[j]] = -1;
else
{
svm_parameter subparam = *param;
subparam.probability=0;
subparam.C=1.0;
subparam.nr_weight=2;
subparam.weight_label = Malloc(int,2);
subparam.weight = Malloc(double,2);
subparam.weight_label[0]=+1;
subparam.weight_label[1]=-1;
subparam.weight[0]=Cp;
subparam.weight[1]=Cn;
struct svm_model *submodel = svm_train(&subprob,&subparam);
for(j=begin;j<end;j++)
{
svm_predict_values(submodel,prob->x[perm[j]],&(dec_values[perm[j]]));
// ensure +1 -1 order; reason not using CV subroutine
dec_values[perm[j]] *= submodel->label[0];
}
svm_free_and_destroy_model(&submodel);
svm_destroy_param(&subparam);
}
free(subprob.x);
free(subprob.y);
}
}
sigmoid_train(prob->l,dec_values,prob->y,probA,probB);
free(dec_values);
free(perm);
}
As with a lot of my code based posts, this is more for my memory than anything, but hopefully may help people unlock the secrets of libSVM.